Quickstart
This page introduces basic Pathfinder usage with examples.
A 5-dimensional multivariate normal
For a simple example, we'll run Pathfinder on a multivariate normal distribution with a dense covariance matrix. Pathfinder can take a log-density function. By default, the gradient of the log-density function is computed using ForwardDiff.
using ADTypes, ForwardDiff, LinearAlgebra, LogDensityProblems,
Pathfinder, Printf, ReverseDiff, StatsPlots, Random
Random.seed!(42)
struct MvNormalProblem{T,S}
μ::T # mean
P::S # precision matrix
end
function (prob::MvNormalProblem)(x)
z = x - prob.μ
return -dot(z, prob.P, z) / 2
end
Σ = [
2.71 0.5 0.19 0.07 1.04
0.5 1.11 -0.08 -0.17 -0.08
0.19 -0.08 0.26 0.07 -0.7
0.07 -0.17 0.07 0.11 -0.21
1.04 -0.08 -0.7 -0.21 8.65
]
μ = [-0.55, 0.49, -0.76, 0.25, 0.94]
P = inv(Symmetric(Σ))
prob_mvnormal = MvNormalProblem(μ, P)Now we run pathfinder.
result = pathfinder(prob_mvnormal; dim=5, init_scale=4)Single-path Pathfinder result
tries: 1
draws: 5
fit iteration: 6 (total: 6)
fit ELBO: 3.84 ± 0.0
fit distribution: MvNormal{Float64, Pathfinder.WoodburyPDMat{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, Matrix{Float64}, Matrix{Float64}, Pathfinder.WoodburyPDFactorization{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, LinearAlgebra.QRCompactWYQ{Float64, Matrix{Float64}, Matrix{Float64}}, LinearAlgebra.UpperTriangular{Float64, Matrix{Float64}}}}, Vector{Float64}}(
dim: 5
μ: [-0.55, 0.49, -0.76, 0.25, 0.94]
Σ: [2.7100000000000017 0.5000000000000001 … 0.06999999999999995 1.0400000000000007; 0.5000000000000003 1.1099999999999994 … -0.16999999999999987 -0.07999999999999963; … ; 0.07000000000000002 -0.16999999999999993 … 0.10999999999999985 -0.21000000000000016; 1.0400000000000005 -0.07999999999999965 … -0.2100000000000001 8.650000000000002]
)
result is a PathfinderResult. See its docstring for a description of its fields.
The L-BFGS optimizer constructs an approximation to the inverse Hessian of the negative log density using the limited history of previous points and gradients. For each iteration, Pathfinder uses this estimate as an approximation to the covariance matrix of a multivariate normal that approximates the target distribution. The distribution that maximizes the evidence lower bound (ELBO) is stored in result.fit_distribution. Its mean and covariance are quite close to our target distribution's.
result.fit_distribution.μ5-element Vector{Float64}:
-0.55
0.49
-0.76
0.25
0.94result.fit_distribution.Σ5×5 Pathfinder.WoodburyPDMat{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, Matrix{Float64}, Matrix{Float64}, Pathfinder.WoodburyPDFactorization{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, LinearAlgebra.QRCompactWYQ{Float64, Matrix{Float64}, Matrix{Float64}}, LinearAlgebra.UpperTriangular{Float64, Matrix{Float64}}}}:
2.71 0.5 0.19 0.07 1.04
0.5 1.11 -0.08 -0.17 -0.08
0.19 -0.08 0.26 0.07 -0.7
0.07 -0.17 0.07 0.11 -0.21
1.04 -0.08 -0.7 -0.21 8.65result.draws is a Matrix whose columns are the requested draws from result.fit_distribution:
result.draws5×5 Matrix{Float64}:
1.29422 -0.136434 -1.17633 0.312551 -0.5837
1.15162 -0.113704 -0.223654 0.553832 -0.151153
-0.232635 0.207321 -0.646822 -1.62273 -0.408372
0.487881 -0.0837587 0.112551 0.217044 0.503958
-2.73478 -1.16278 1.34925 4.80505 2.05691We can visualize Pathfinder's sequence of multivariate-normal approximations with the following function:
function plot_pathfinder_trace(
result, logp_marginal, xrange, yrange, maxiters;
show_elbo=false, flipxy=false, kwargs...,
)
iterations = min(length(result.optim_trace) - 1, maxiters)
trace_points = result.optim_trace.points
trace_dists = result.fit_distributions
anim = @animate for i in 1:iterations
contour(xrange, yrange, exp ∘ logp_marginal ∘ Base.vect; label="")
trace = trace_points[1:(i + 1)]
dist = trace_dists[i + 1]
plot!(
first.(trace), getindex.(trace, 2);
seriestype=:scatterpath, color=:black, msw=0, label="trace",
)
covellipse!(
dist.μ[1:2], dist.Σ[1:2, 1:2];
n_std=2.45, alpha=0.7, color=1, linecolor=1, label="MvNormal 95% ellipsoid",
)
title = "Iteration $i"
if show_elbo
est = result.elbo_estimates[i]
title *= " ELBO estimate: " * @sprintf("%.1f", est.value)
end
plot!(; xlims=extrema(xrange), ylims=extrema(yrange), title, kwargs...)
end
return anim
end;xrange = -5:0.1:5
yrange = -5:0.1:5
μ_marginal = μ[1:2]
P_marginal = inv(Σ[1:2,1:2])
logp_mvnormal_marginal(x) = -dot(x - μ_marginal, P_marginal, x - μ_marginal) / 2
anim = plot_pathfinder_trace(
result, logp_mvnormal_marginal, xrange, yrange, 20;
xlabel="x₁", ylabel="x₂",
)
gif(anim; fps=5)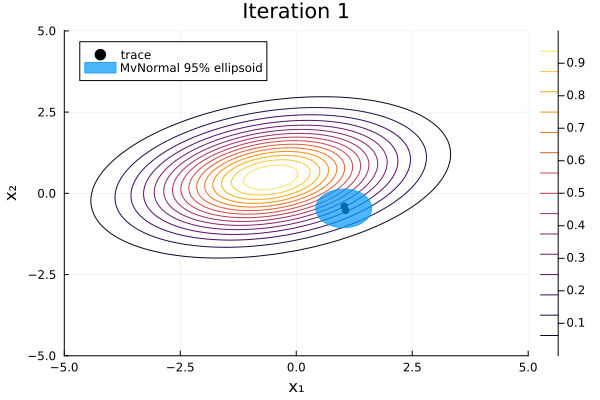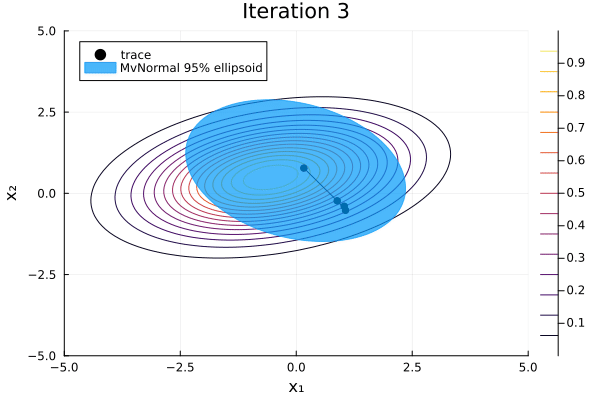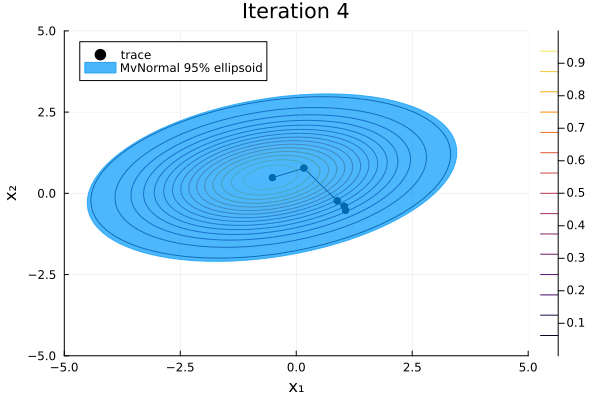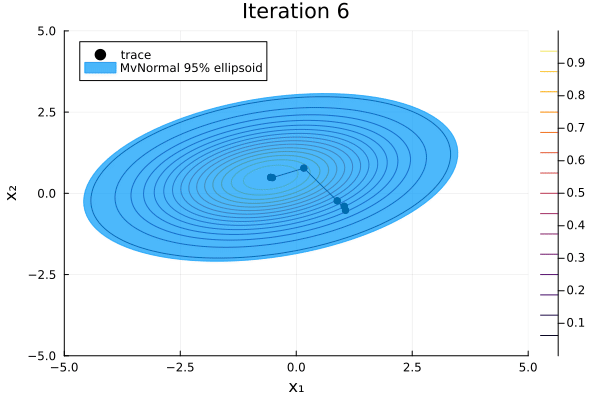
A banana-shaped distribution
Now we will run Pathfinder on the following banana-shaped distribution with density
\[\pi(x_1, x_2) = e^{-x_1^2 / 2} e^{-5 (x_2 - x_1^2)^2 / 2}.\]
Pathfinder can also take any object that implements the LogDensityProblems interface interface. This can also be used to manually define the gradient of the log-density function.
First we define the log density problem:
Random.seed!(23)
struct BananaProblem end
function LogDensityProblems.capabilities(::Type{<:BananaProblem})
return LogDensityProblems.LogDensityOrder{1}()
end
LogDensityProblems.dimension(::BananaProblem) = 2
function LogDensityProblems.logdensity(::BananaProblem, x)
return -(x[1]^2 + 5(x[2] - x[1]^2)^2) / 2
end
function LogDensityProblems.logdensity_and_gradient(::BananaProblem, x)
a = (x[2] - x[1]^2)
lp = -(x[1]^2 + 5a^2) / 2
grad_lp = [(10a - 1) * x[1], -5a]
return lp, grad_lp
end
prob_banana = BananaProblem()and then visualise it:
xrange = -3.5:0.05:3.5
yrange = -3:0.05:7
logp_banana(x) = LogDensityProblems.logdensity(prob_banana, x)
contour(xrange, yrange, exp ∘ logp_banana ∘ Base.vect; xlabel="x₁", ylabel="x₂")
Now we run pathfinder.
result = pathfinder(prob_banana; init_scale=10)Single-path Pathfinder result
tries: 1
draws: 5
fit iteration: 9 (total: 17)
fit ELBO: 0.56 ± 0.37
fit distribution: MvNormal{Float64, Pathfinder.WoodburyPDMat{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, Matrix{Float64}, Matrix{Float64}, Pathfinder.WoodburyPDFactorization{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, LinearAlgebra.QRCompactWYQ{Float64, Matrix{Float64}, Matrix{Float64}}, LinearAlgebra.UpperTriangular{Float64, Matrix{Float64}}}}, Vector{Float64}}(
dim: 2
μ: [0.4243163938264882, 0.10390110727330021]
Σ: [0.42319919978439585 0.5889776730603031; 0.5889776730602974 0.9635442593820437]
)
As before we can visualise each iteration of the algorithm.
anim = plot_pathfinder_trace(
result, logp_banana, xrange, yrange, 20;
xlabel="x₁", ylabel="x₂",
)
gif(anim; fps=5)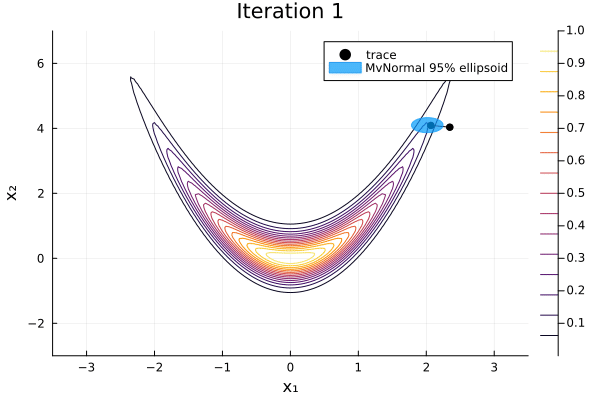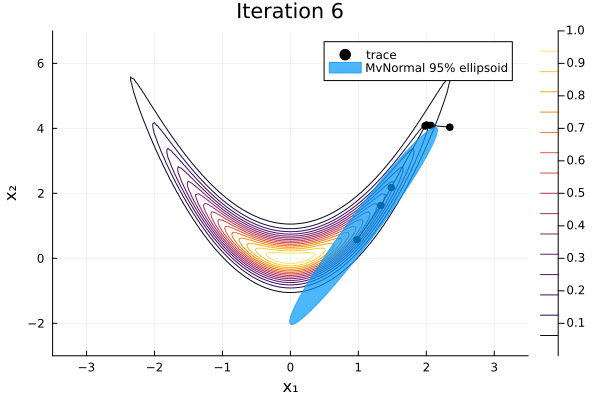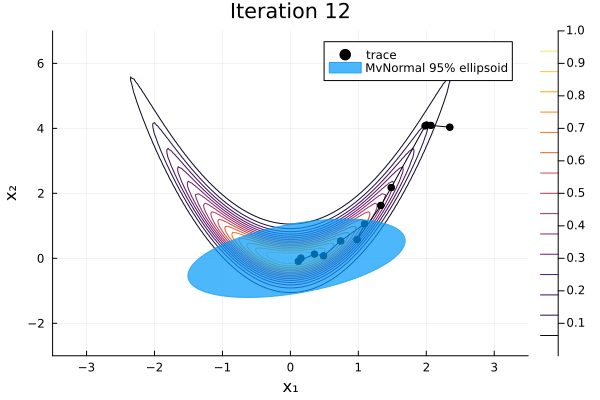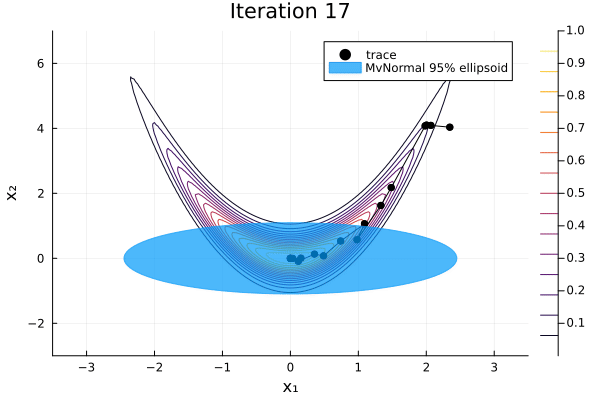
Since the distribution is far from normal, Pathfinder is unable to fit the distribution well. Especially for such complicated target distributions, it's always a good idea to run multipathfinder, which runs single-path Pathfinder multiple times.
ndraws = 1_000
result = multipathfinder(prob_banana, ndraws; nruns=20, init_scale=10)Multi-path Pathfinder result
runs: 20
draws: 1000
Pareto shape diagnostic: 0.93 (bad)result is a MultiPathfinderResult. See its docstring for a description of its fields.
result.fit_distribution is a uniformly-weighted Distributions.MixtureModel. Each component is the result of a single Pathfinder run. It's possible that some runs fit the target distribution much better than others, so instead of just drawing samples from result.fit_distribution, multipathfinder draws many samples from each component and then uses Pareto-smoothed importance resampling (using PSIS.jl) from these draws to better target prob_banana.
The Pareto shape diagnostic informs us on the quality of these draws. Here the Pareto shape $k$ diagnostic is bad ($k > 0.7$), which tells us that these draws are unsuitable for computing posterior estimates, so we should definitely run MCMC to get better draws. Still, visualizing the draws can still be useful.
x₁_approx = result.draws[1, :]
x₂_approx = result.draws[2, :]
contour(xrange, yrange, exp ∘ logp_banana ∘ Base.vect)
scatter!(x₁_approx, x₂_approx; msw=0, ms=2, alpha=0.5, color=1)
plot!(xlims=extrema(xrange), ylims=extrema(yrange), xlabel="x₁", ylabel="x₂", legend=false)
While the draws do a poor job of covering the tails of the distribution, they are still useful for identifying the nonlinear correlation between these two parameters.
A 100-dimensional funnel
As we have seen above, running multi-path Pathfinder is much more useful for target distributions that are far from normal. One particularly difficult distribution to sample is Neal's funnel:
\[\begin{aligned} \tau &\sim \mathrm{Normal}(\mu=0, \sigma=3)\\ \beta_i &\sim \mathrm{Normal}(\mu=0, \sigma=e^{\tau/2}) \end{aligned}\]
Such funnel geometries appear in other models (e.g. many hierarchical models) and typically frustrate MCMC sampling. Multi-path Pathfinder can't sample the funnel well, but it can quickly give us draws that can help us diagnose that we have a funnel.
In this example, we draw from a 100-dimensional funnel and visualize 2 dimensions.
using ReverseDiff, ADTypes
Random.seed!(68)
function logp_funnel(x)
n = length(x)
τ = x[1]
β = view(x, 2:n)
return ((τ / 3)^2 + (n - 1) * τ + sum(b -> abs2(b * exp(-τ / 2)), β)) / -2
endFirst, let's fit this posterior with single-path Pathfinder. For high-dimensional problems, it's better to use reverse-mode automatic differentiation. Here, we'll use ADTypes.AutoReverseDiff to specify that ReverseDiff.jl should be used.
result_single = pathfinder(logp_funnel; dim=100, init_scale=10, adtype=AutoReverseDiff())Single-path Pathfinder result
tries: 1
draws: 5
fit iteration: 9 (total: 821)
fit ELBO: 89.03 ± 0.73
fit distribution: MvNormal{Float64, Pathfinder.WoodburyPDMat{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, Matrix{Float64}, Matrix{Float64}, Pathfinder.WoodburyPDFactorization{Float64, LinearAlgebra.Diagonal{Float64, Vector{Float64}}, LinearAlgebra.QRCompactWYQ{Float64, Matrix{Float64}, Matrix{Float64}}, LinearAlgebra.UpperTriangular{Float64, Matrix{Float64}}}}, Vector{Float64}}(
dim: 100
μ: [-0.8014495171678351, 0.020324954372878512, 0.09459561344576994, 0.04766384426115, -0.09918085280790656, 0.08064766332498374, 0.015466522080503503, 0.09539001462606711, 0.03536775725303409, 0.04502830707753436 … -0.028836747821826936, -0.006793509059832628, -0.030058219182856227, -0.04275200501427223, 0.090879110121183, -0.011749024234960409, 0.0009891959180377344, 0.03001753650736283, -0.032282116524803006, -0.009760797772017132]
Σ: [0.027932355988361756 -2.8036555438287758e-5 … 4.450470204881568e-5 1.3468168569688577e-5; -2.8036555438287758e-5 0.4643840110941755 … -0.00010004211046971308 -3.6282157799570613e-5; … ; 4.450470204881568e-5 -0.0001000421104697339 … 0.4695415593708684 5.1282653609863e-5; 1.3468168569705924e-5 -3.628215779957235e-5 … 5.1282653609863e-5 0.4617323854346034]
)
Let's visualize this sequence of multivariate normals for the first two dimensions.
β₁_range = -5:0.01:5
τ_range = -15:0.01:5
anim = plot_pathfinder_trace(
result_single, logp_funnel, τ_range, β₁_range, 15;
show_elbo=true, xlabel="τ", ylabel="β₁",
)
gif(anim; fps=2)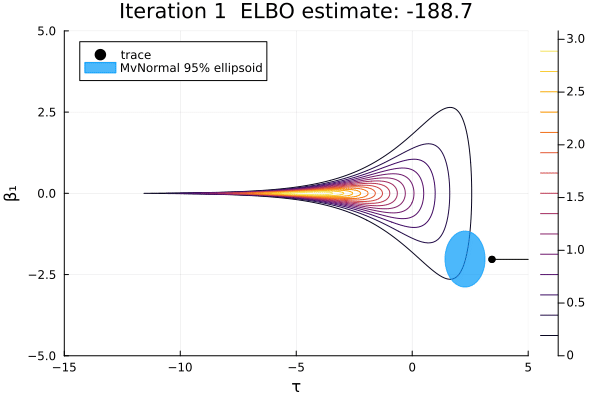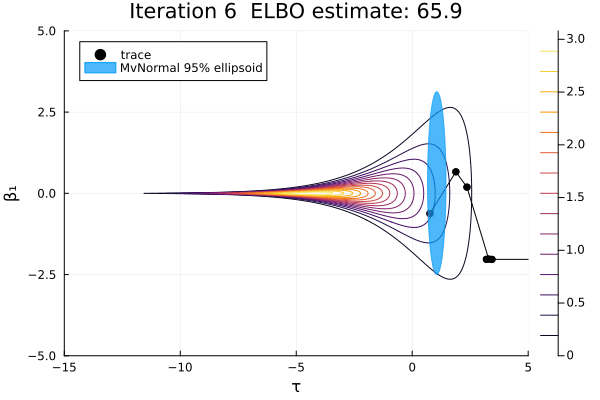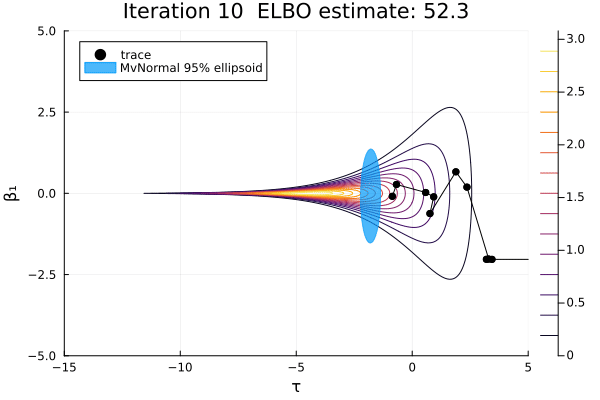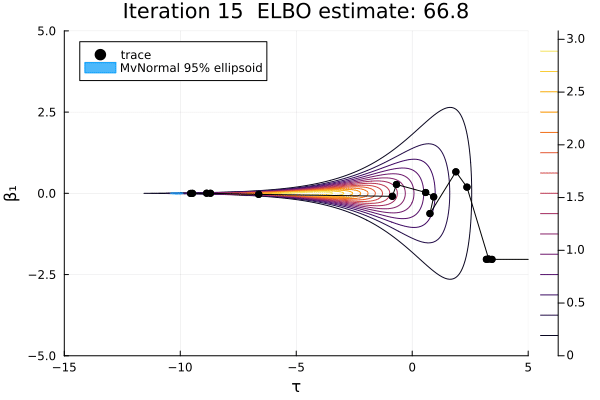
For this challenging posterior, we can again see that most of the approximations are not great, because this distribution is not normal. Also, this distribution has a pole instead of a mode, so there is no MAP estimate, and no Laplace approximation exists. As optimization proceeds, the approximation goes from very bad to less bad and finally extremely bad. The ELBO-maximizing distribution is at the neck of the funnel, which would be a good location to initialize MCMC.
Now we run multipathfinder.
ndraws = 1_000
result = multipathfinder(logp_funnel, ndraws; dim=100, nruns=20, init_scale=10, adtype=AutoReverseDiff())Multi-path Pathfinder result
runs: 20
draws: 1000
Pareto shape diagnostic: 0.69 (ok)Again, the poor Pareto shape diagnostic indicates we should run MCMC to get draws suitable for computing posterior estimates.
We can see that the bulk of Pathfinder's draws come from the neck of the funnel, where the fit from the single path we examined was located.
τ_approx = result.draws[1, :]
β₁_approx = result.draws[2, :]
contour(τ_range, β₁_range, exp ∘ logp_funnel ∘ Base.vect)
scatter!(τ_approx, β₁_approx; msw=0, ms=2, alpha=0.5, color=1)
plot!(; xlims=extrema(τ_range), ylims=extrema(β₁_range), xlabel="τ", ylabel="β₁", legend=false)